オペアンプの仕組みと内部回路を考える
はじめに
アナログ回路の話になるとオペアンプが出てくる。
イマジナリーショートがわかれば設計はできてしまうけど...頭良くないからこれも素直に受け入れられない。
「オペアンプで負帰還をかけた場合にプラス入力とマイナス入力との端子間に電位差が無い状態」まではよく聞くが、まず「なんでそうなる?」って思う。
オペアンプの内部を回路シミュレーター(LTspice)で再現して理解を深める。
解析対象
NJM4558(新日本無線)のオペアンプの内部回路をデータシートの図を拝借し以下に示す。

各部の役割は以下の通りと考えられる。

トランジスタの入力にはカレントミラーがあり、この仕組みがイマジナリーショートのおおよその正体だと思われる。
LTspiceによる再現
LTspiceを用いて、オペアンプを再現してみた。上はトランジスタとダイオードなど素子で再現したオペアンプ。
下にちょこっとオペアンプの素子を対比で置いてある。
反転増幅回路、電圧4倍となる回路とし、波形の緑は入力・青は出力としている。

注記:以下は各部の考察ですが、鵜呑みにしないでください。
アナログ回路の知識が乏しい人が書いています。
シミュレータでなんとか回路を再現できましたが、よくわかっていません。
1.定電流リファレンスとカレントミラー

定電流を生成し、カレントミラーを用いて各増幅回路に分配する。
1-1.定電流リファレンス
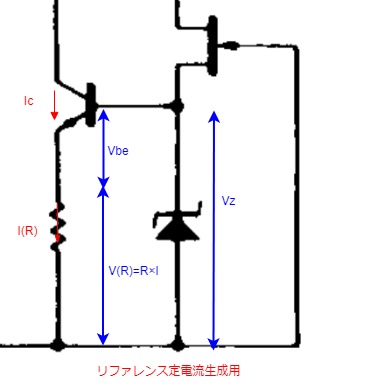
<動作概要>
定電圧ダイオードを用いているため、Vzは一定となる。
よって、トランジスタのVbeとIc、Ic=I(R)のためV(R)が決まる。
これらは定電圧ダイオードにより、Vbe,VR,Icが一定に保たれる。
<理論式>
抵抗にかかる電圧は$V R = V z - V {be}$でこの値は一定となる。
定電流値は抵抗値を決めることで設定できる。$I R (=I _C)$は以下のように求められる。
$$ V_R = I_R \times R $$
$$I_R \times R = V_z - V _{be}$$
$$I_R = \frac{V_z - V_be}{R}$$
$$I_R (=I_C)$$より
$$I_C = \frac{V_z - V_{be}}{R}$$
ターゲットとする定電流を決め、VbeとIcをトランジスタの特性から読み出し、抵抗の定数を決める。
<その他>
JFETにはVgsに-Vzの電圧がかかり、Vgsに応じた一定の電流を流す役割を担うと思われる。(Vdd-Vzの電圧降下を回収)
1-2.定電流カレントミラー

<動作概要>
定電流リファレンスの電流は一番右のノードにあたる。
PNPダイオードのコレクタとゲートが短絡されたカレントミラーの形をとり、電流がIc1,Ic2にコピーされる。
これを各部の電流源としている。
<理論式>
各ノードのVbeは等しくなるため、各ノードのIcも等しくなるため、リファレンス電流がコピーされる。
$$V_{beREF} = V_be1 = V_be2$$
$$ I_REF = I_c1 = I_c2 $$
<その他>
Ic1の電流値
Ic1はトランジスタのエミッタ側に抵抗が存在するため、抵抗の電圧降下でVbeが低下しIc1が絞られる。
定電流源であるが、リファレンスノード電流に比例した定電流が供給されると考えられる。各ノードのベース電流の行先 ベース電流はリファレンスノードに回収される。

2.入出力部と増幅部

以下の3つのブロックに分けて考える。
- 差動増幅回路とカレントミラー
- エミッタフォロワ反転増幅回路
- プッシュプル回路
赤枠で示した位相補償に関しては後述する。
2-1.入力部

<動作概要>
- 差動増幅部とカレントミラーから構成される。上部にはカレントミラーによる定電流源がある。
- -INPUTと+INPUTに電位差が発生するとVbe,Vce,Icの値が変化する。電位差がない場合は左右の電流は等しい。
- 電位差により、左右に供給される電流の割合が変化するが、下部のカレントミラーには同じ電流が流れる。
- そのため、差分の電流が次段の増幅回路に供給される。次の段に流れる電流は入力が等しい場合に流れる定常電流と電流の割合の差分である。
<その他>
- 反転増幅の場合
- INPUT-の電位が上がる→Vbe値が圧迫され下がり、電流が減る→INPUT+の電流とVbeが増える→電流の差分(+)が反転増幅→フィードバックで減らすように調整
- INPUT-の電位が下がる→Vbe値が圧迫され上がり、電流が増える→INPUT+の電流とVbeが減る→電流の差分(-)が反転増幅→フィードバックで増えるように調整
2-2.増幅部

<動作概要>
前段のエミッタフォロワで電流を増幅する。
後段は反転増幅回路でエミッタ抵抗を0とすると電圧の増幅度が限りなく大きくなる。
<理論式>
前段のトランジスタを1,後段のトランジスタを2とする。
$$I_e1 = hfe \times (I±ΔI) $$
後段のトランジスタのベース電流は、
$$I_b2 = hfe \times (I±ΔI) - I_R1 $$
さらに反転増幅を行い、
$$I_e2 = hfe\times ( hfe \times (I±ΔI) - I_R1 )$$
トランジスタを二段構成とすることで、電流の増幅率が大きくなる。
たとえばhfe=380であれば$$380 \times 380=144400$$倍の増幅率を得る。
2-3.出力部

<動作概要>
- プッシュプルエミッタフォロワで構成される。
- 出力インピーダンスを下げ、クロスオーバーひずみをなくすためと考えられる。
- 電圧を中間のオフセットで出力する。
関連記事
FF(フリップフロップ)を再現した記事
アナログ回路とデジタル回路の違いを考える
はじめに
入社して、数日目ぐらいに
「うちの開発1課と隣の開発2課は何が違うんですか?」
「君のいる1課はデジタル回路で2課はアナログ回路の部署なんだよ」
「なるほどです」(ふーん。ふーん?ふーん???)
今まで上記を素直に受け入れられず、何が違うんだろうと考えてきた。
自分なりに考えを一回整理してみる。
目次
<メイントピック>
- とりあえず結論
- なんでデジタル回路が生まれたの?
- アナログ回路とデジタル回路のたとえ
- アナログ回路の中のデジタル回路
- アナログ回路とデジタル回路の情報
- デジタル回路のメリット
<勝手に考えてみた>
- そもそもなんでデジタル回路が必要なの?
- コンピュータシステム
- デジタル回路設計の都合(たくさんの信号を扱う
- デジタル回路の高速化(結局アナログの概念に戻りつつある?)
<注記>
※この記事は勉強不足で正しくないかもしれません。デジタル回路アナログ回路は人によってい考え方が違ったり、曖昧に使われているものかもしれません。
前置き
電気は熱や光を発生させたり、何かを動かしたり、情報を伝達したりする。
そのうちの「情報」を扱う中でデジタル回路、アナログ回路という概念があるみたい。
情報を扱う以外の回路は強いて言えばアナログ回路(デジタル回路じゃない)とみなされるようだ。
とりあえず結論
アナログ回路の信号にはどの時間にどの電圧(または電流)であったかが情報として含まれる。
デジタル回路はこの信号の情報(電気・時間)をまとまった範囲で扱うことにより、情報の劣化を防ぐ。

アナログ信号は連続的に変化する電気信号だが、デジタル回路は有限個の信号レベル(0と1)である。
ここまではよく言われるが、デジタル回路はタイミングをそろえることで時間の概念も有限個として扱っていると思ってる。
アナログは連続的、デジタルは離散的と考えられるが、デジタル回路も突き詰めればアナログ回路の集まりである。
なんでデジタル回路が生まれたの?(推測含む)
19世紀、エジソンが電球を発明したあたりではデジタル回路という概念はなかったはずである。
いつからか、たぶん誰か電気を使って計算できないか考え始めた。手で計算するのめんどくさいよね。
そして1937年にクロード・シャノンが「継電器及び開閉回路の記号的解析」において、電気回路(ないし電子回路)が論理演算に対応することを示した。
これがデジタル回路の始まりと言われている。この延長にコンピュータシステムがあって、デジタル回路は今日の情報化社会を支えている。

トランジスタがあれば論理回路ができて、論理回路があれば加算器ができる。
加算ができれば減算ができ、加算減算ができれば掛け算割り算もできる。
四則演算ができれば、微分積分などあらゆる計算ができる。
情報を扱うアナログ回路は最後はコンピュータシステムによって検出される。
デジタル回路はやはり演算するコンピュータシステム(と人間)の都合だと考えることもできると思う。
アナログ回路とデジタル回路のたとえ
まず怪しいたとえ話から入ります。2834ml入る桶に2834mlピッタリ入っています。
これをこぼさず10m運びましょう。途中には汚水の雨が降っています。

きっと10m先では水もこぼれているだろうし、汚水も入っているかもしれません。
邪魔しないように静かにして、道に屋根をつけてあげました。
それで頑張っても2834mlがきっと2500mlになっちゃうでしょう。
これは困った。このままでは要求を満たせません。
するとADCさんが現れてこう言いました。
2834mlという情報を正確に渡せれば良いんでしょう。情報を12人で分けましょう。

これでうまく情報を運ぶことができました。しかし人手がたくさん必要でした。
アナログ回路の中のデジタル回路
電気回路には以下の4つの素子しかありません。
主にアナログ回路は上記の素子で作られます。
もちろんデジタル回路も上記の素子で作られます。
じゃあ使われる素子は同じだけどその使い方で異なるのであろう。
すべては連続的に変化する電気信号であるため、アナログ回路といえると思う。
その中でも連続的に変化するけれど、有限個の信号レベル(0と1)を扱うものをデジタル回路としているっぽい。

アナログは電気信号が連続的に変化するが、デジタル回路は時間、電圧レベル共に離散的に扱っている。
しかし、突き詰めていくとそれは連続的に変化する信号の集まりです。
アナログ回路の情報とデジタル回路の情報
ある連続的なアナログ信号を考えてみます。
ある時間を取り出して、電圧を測って、これを12本の信号に分解します。
これを行うのかADCさんです。
AnalogDigitalConverterはそのままアナログデジタル変換器という意味です。

ここで10mVのノイズが乗ってきてしまったとしましょう。
アナログ信号2834mVは2844mVになり、情報が変化します。

しかしデジタル信号は0~1Vは0とし,2V以上で1と判断する場合、10mVのノイズが乗ってもデータは変わりません。
つまりデジタル回路のほうがノイズに強いのです。
しかし、トレードオフもあります。
信号1本で伝えられる情報が12本になってしまいました。
信号線が増えるだけでなく、このデータの処理に携わるトランジスタの数が多くなります。
時間と電圧の情報を細かく分解しすぎても大変です。
あまりに細かすぎると物理的に厳しいですが、たいていは情報を必要な分取ります。

電圧も必要な細かさ(分解能)で時間も必要な細かさ(サンプリングレートで)取ります。
細かければ細かいほど、コストとかエネルギーが多くなってしまうのでバランスが大切。
デジタル回路にした時の良いところ
ここまででデジタル回路は、
- メリット:ノイズに強い
- デメリット:信号線とトランジスタ数が多くなる
しかし最近は半導体の微細加工技術の向上により、トランジスタ1個がどんどん小さく安く作られるようになっています。
そのため、トランジスタが増えることのデメリットは少なくなってきました。
そしてノイズの影響を受け、自由に特性を変えることができないアナログ回路をデジタル回路に代替えするようになり、今までアナログ回路で行っていた処理をデジタルデータで行うなども多くなってきています。
以下、勝手に考えてみた内容
そもそもなんでデジタル回路が必要なの?
コンピュータシステムとの相性
1937年にクロード・シャノンが「継電器及び開閉回路の記号的解析」において、電気回路(ないし電子回路)が論理演算に対応することを示した。ここが始まりのようだ。クロード・シャノンはデジタル回路設計の創始者と言われているみたい。コンピュータの処理は莫大な量の論理演算を行うため、デジタル回路(CPU)を内蔵している。
現代のコンピューターがプログラム内蔵方式のディジタルコンピュータである。
順次命令文を実行させて、限られたHWにて様々な処理ができるようになっている。
限られたHWを何度も活用するために、クロックという概念があり、フリップフロップ(FF)は時間のまとまりで扱うことを可能にしている。
→タイミングの記事 manaka1122.hatenablog.com
→コンピュータアーキテクチャの記事を書きたい(準備中)
たとえば...
CPU:64bit → 0とか1のデータを64bitそろえて処理しますよ
動作クロック:1GHz → データを1nsごとにまとまりにして処理をしていますよ
どんなところで使われているの?
よく言われるのが、RF(無線)関連です。それ以外にもセンサから出てくる情報はまずアナログ信号だったりします。

無線は振幅とか位相情報をある程度まとまりとして扱うので、この記事の説明とは矛盾してしまうかもです。
デジタル回路設計の都合(たくさんの信号を扱う)
デジタル回路という概念はどういった意味合いを含んでいるんだろう?
アナログ回路は少しのノイズでデータが変わってしまうので、とても気を使います。
でもデジタルデータはノイズが乗っても簡単には変わらないし、多少は雑に扱えます。しかし、本数はとんでもなく多いです。
なので、電気信号をデジタル(0,1とクロックごとの時間のまとまり)と考え、アナログに比べて設計を簡略化しているように感じる。
デジタル回路の高速化
デジタル回路が数十MHz程度で動いていた時代は良かったのですが、今は平然とGHzで動きます。
(もちろん数十MHzでもエッジ部分の周波数成分は高くノイズの考慮も大変だと思います。)
CPUの動作クロックも速ければ、インターフェースのクロックも速くなります。
またアナログ回路を吸収することもデジタル回路が高速にしており、これもデジタル回路設計の難易度が上げています。
(たとえば数GHz~数十GHzのシリアル信号を複数レーン、DDRのバススピードなど)
FPGAがプログラムできる仕組み
最初に
FPGAとはプログラムできる回路ですとよく言われる。それはなんとなくわかるけど、じゃあ「プログラムできる回路ってなんだ?」という疑問が生まれてくる。
とくにソフトの方から良く聞かれることがあるので、自分なりにまとめてみた。
とりあえず結論
プログラムできる回路というのはANDとかORとかの論理回路が自由に組み合わせられることである。
この論理回路の組み合わせはLUTに書き込み値によって自由に変えることができる。
目次
以下の順序で見ていこうと思う。
- FPGAの構成
- 論理ブロック
- LUT(ルックアップテーブル)☆ここがメイン
FPGAの構成
FPGAの構成をざっくり以下に示してみる。

まずIOB(入力出力ブロック)から、信号が入ってくる。
次にSB(スイッチブロック)やCB(コネクションブロック)を介して該当のLB(論理ブロック)まで配線される。
LBで何らかの論理回路を通った後、別のLBなどをたくさん通って、最後はIOBから出力される。
では、このロジックブロックとは何だろうか?
論理ブロック(Logic Block)
論理ブロックの構成を以下に示してみる。

LUT(ルックアップテーブル)とFF(フリップフロップ)から構成される。
LUTとは任意の論理回路となるプログラマブルの要である。
ここについてもう少し詳しくみていく。
ちなみにFFはFPGAがデジタル回路としてタイミングを調停するために重要である。
FPGA内は書いたプログラムが物理配線に相当するので、FFをうまく使ってタイミングを完全に達成することが大事である。
この記事ではタイミングの概念には触れない。 (最後の関連記事参照)
LUT(ルックアップテーブル)
このLUT(ルックアップテーブル)がプログラマブル回路を実現している部分である。
まずA入力とB入力があり、出力結果はfとする。
これがANDとかORとかXORとか自由自在に変えられることを順々に見ていく。
まずAとBの論理積(AND)を考えてみる。
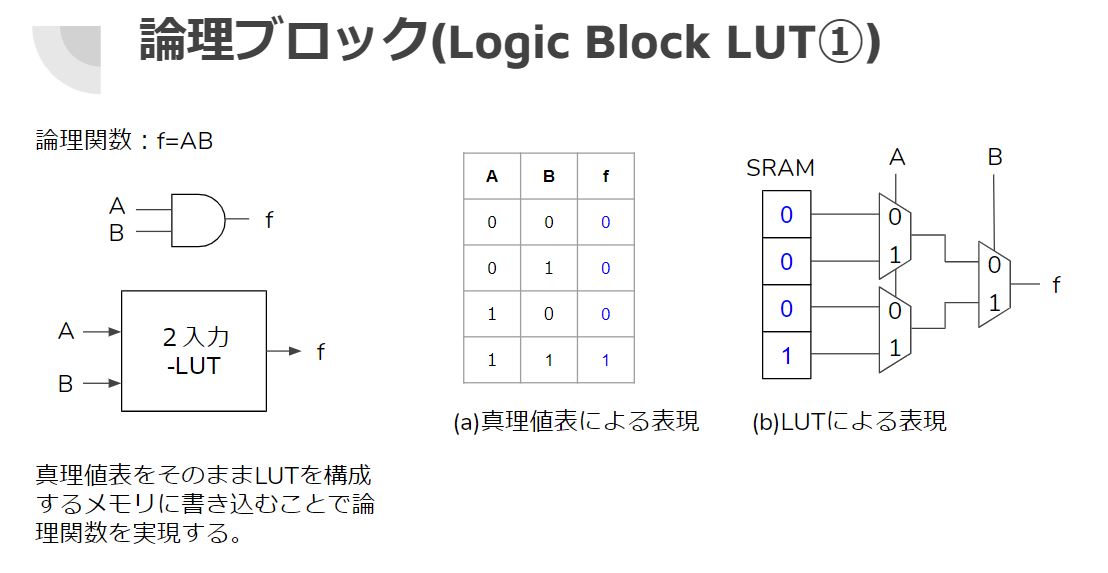
真ん中の(a)は真理値表を示している。
次に(b)のLUT表現を見てみる。
真理値表より4つのパターンがあるので4つのメモリを準備する。
ここには論理積(AND)の結果が格納されている。
右側にはセレクタがあり、各信号が「0の時は0側」「1の時は1側」の信号が反映される。
たとえば
- AもBも0の時は、一番上の0の値が出力される。
- A=1,B=0の時は、2番目の0の値が出力される。
- A=0,B=1の時は、3番目の0の値が出力される。
- A=1,B=1の時は、一番下の1の値が出力される。
つまりこれでAND回路が実現されたのである。
メモリに入れる値を上から「0,0,0,1」でなく、「0,1,1,1」とした場合、論理和(OR)になるし、「0,1,1,0」としたら排他的論理和(XOR)になる。
こうしてメモリに入れる値を変えることで、任意の論理回路が作れるのである。
実際のFPGAにはこのような仕組みが数千~100万以上入っているのである。
LUTの実際
3入力-LUTを書いてみると以下のような感じになる。
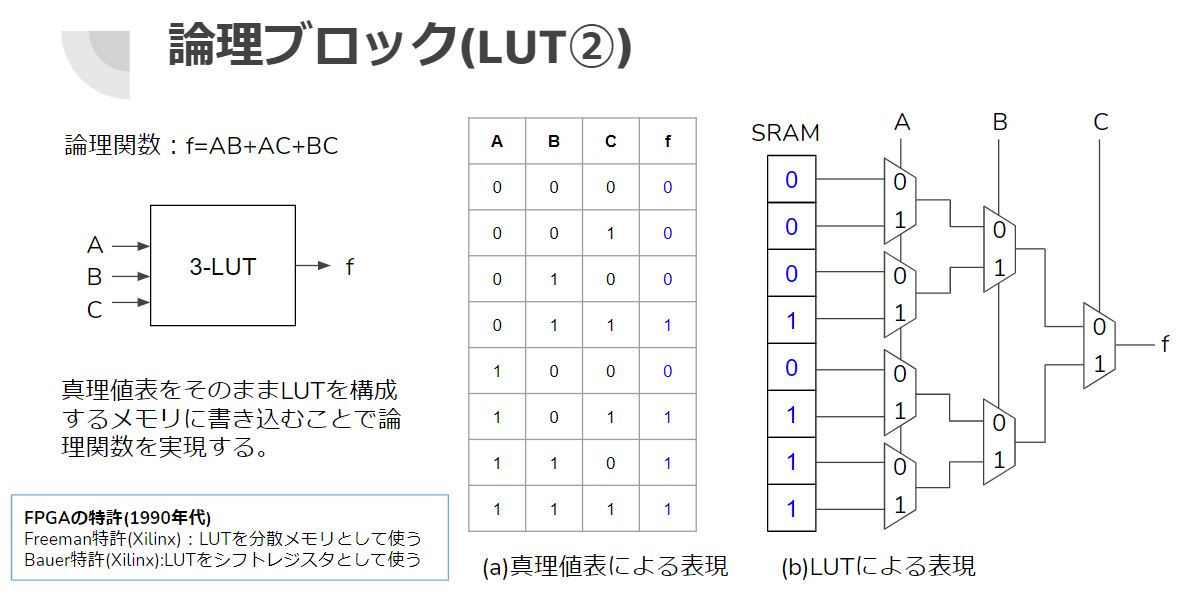
実際のFPGAでは4入力/6入力/8入力のLUTが使われている。
最後に...
とりあえずFPGAのプログラムできる仕組みはざっくりこんな感じである。
ASICではAND回路がトランジスタ6個で済むところ、FPGAではLUTの仕組みを消費することになる。(RAMとセレクタなどでも少なくとも50個以上?)
これがASICにスピードもトランジスタの個数も及ばない理由なのかなと思う。
但し、最新のプロセス技術(10nm前後)ではASICではマスク代などがとんでもない額になってしまうので、なかなか使えない。
しかしFPGAはたくさん作っていろいろな業界で使われているので、半導体プロセスの成長に伴いFPGAを採用する事例が増えているのかもしれない。
関連記事
タイミングの概念 manaka1122.hatenablog.com
論理回路をトランジスタレベルで再現(OR,AND...DFF) manaka1122.hatenablog.com
参考資料
・FPGAの原理と構成 天野英晴(編集)共著(14人)
・デジタル回路設計とコンピュータアーキテクチャ
David Money Harris (著), Sarah L. Harris (著),
鈴木 貢 (翻訳), 天野 英晴 (翻訳), 中條 拓伯 (翻訳), 永松 礼夫 (翻訳)
電気素子を考える:抵抗編
電気素子:抵抗編
どのような電気回路も分解していくと以下の4つしか存在しない。
ひとつひとつの理解を深めていく。 最初は抵抗編。
抵抗(Resistor)
役割
抵抗の役割は主に以下のような感じである。
- 適切な電流を調整すること
- 電圧を分ける
- 発熱する
もし電流を調整しなければバッテリなどすぐに空になってしまう。(その前に熱で壊れる?)
電流の調整
まず抵抗のみの簡単な回路を考える。
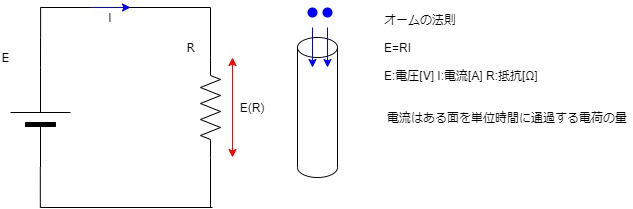
例えば
- ここに3Vを加えて1Ωの抵抗とすれば、電流は1Aとなる。(E=RI 3=1×I I=3)
- ここに3Vを加えて3Ωの抵抗とすれば、電流は1Aとなる。(E=RI 3=3×I I=1)
これらはオームの法則として知られている。
電流を調整しLEDをつけたり、モーターを動かしたり、ヒーター熱を発生させたりする。
電圧を分ける
今度は抵抗2つの簡単な回路を考える。
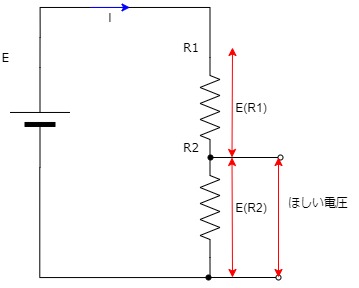
ここに電圧3Vを加えると、抵抗2つで3Vを使うしかない。
またループする電流は一定である。
例えば
ここに3Vを加えて3Ω、3Ωの抵抗とすれば、1周で6オームのため電流は0.5Aとなる。 (E=RI 3=(3+3)×I 3=6×I I=0.5)
それぞれの抵抗には0.5A×3Ωで1.5Vがかかる。
電圧の比率は抵抗の比率を変えることによって、欲しい電圧を得るように操作できる。
あとは取り出すときにロスを無くすために、どのぐらい電流を流せば十分かというところが大事になってくる。
定格電力
LED、モーター、ヒーターを動かすには電気エネルギーが必要になる。 電気エネルギーは電圧と電流で表される。
P(W)=V(V)・I(A)
たとえば、電圧3V,抵抗3Ωとすれば、電流は1Aとなるので
P(W)=V(V)・I(A) = 3V×1A=3W
となる。
この抵抗の消費電力は3Wということになる。
この電力は、抵抗の場合すべて熱となって放射されるため、消費電力が大きすぎると抵抗体そのものの温度が上昇し、最後には焼き切れたり、溶けだしたりする。
そのため、何Wまで電力を消費できる抵抗器なのかを示す必要があり、これを表したものが抵抗器の定格電力である。
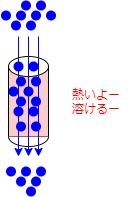
抵抗焼損などに対する安全性を考えて、定格電力の1/2以下の消費電力で使用されるのがふつうみたい。
1005(縦1mm×横0.5mm)以下の小さいチップ抵抗器などを使っていると、意外と定格電力に対して危ない時がある。
抵抗器の構造
チップ抵抗の構造を簡単に書いてみる。

この抵抗体の断面積や長さや使用する物質の固定抵抗で抵抗値を調整している。
使用する物質と断面積と長さの関係は次式で示される。
電気抵抗 R=ρ・L/S [Ω]
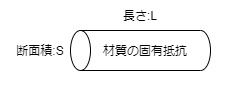
- 断面積[cm2]:S
- 長さ[cm]:L
- 物質の固有抵抗[Ω・cm]:ρ
どんなものにも抵抗がある
さて抵抗について考えてきましたがどんなものにも抵抗はある。
それは基板上でも、鉄塔で長い距離をつないでいる伝送も同じである。
基板の銅箔パターンの抵抗
基板上でも細く長いパターンは損失が大きくなる。
これは細く長いケーブルでも同様。
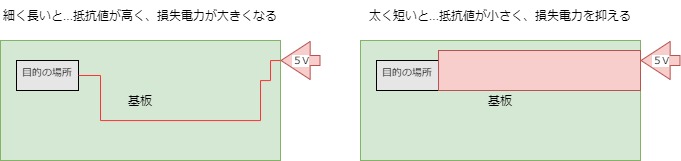
実際は基板上では直流~GHz(109)単位の周波数の信号が存在する。
これらの信号が住みよくなるように考慮しつつ、電源分配も最適化しつつ、
コストのため層数も少なく...大体理想的に引けず妥協を迫られる。
送電
抵抗について考えていくと、なぜ送電に高圧を使うのかも理解できる。

電柱とか長距離送電の鉄塔は、距離は変えられない。
ケーブルは太くすると、材料費も高いし、工事も大変そう。(細すぎても耐久性とかあるかも)
抵抗成分は避けられないけど大量のエネルギーは送らなくてはならない。
そうすると電圧を高くしていき、流れる電流を減らしつつ、同じ量のエネルギーを送る。(E=RI)
損失エネルギーはP=I2×Rとなるので電圧を上げて電流を減らすと、送電の損失を減らすことができる。
実際は交流だし、3相交流などでさらなる工夫もあるようだ。
最終的には変圧器で家庭で使う交流100Vにするが電柱は数千ボルトで送電している。
その他
抵抗はE系列から選ぶ
なんでも好きな抵抗を回路図に書いていると、抵抗器の製造業者があんまり作っていないものでコストが高かったり手に入りにくかったりする。
なので使用する抵抗はできるだけE系列に応じて選定する。
- E系列の参考リンク(KOA)
https://www.koaglobal.com/product/library/resistor/marking
参考資料
https://www.rohm.co.jp/electronics-basics/resistors/r_what1
https://www.koaglobal.com/product/library/resistor/basic
https://article.murata.com/ja-jp/article/what-is-resistor
Seeed Fusion によるMCU基板製造
概要
Seeed Fusion にて$4.9で基板が作成できるらしいので実際にやってみる。
背景
ArtWorkの勉強のために実施。
仕事などで回路設計はするがAWは指示と確認のみである。
少しでもAWの苦労を実感したほうが良いと思った。
(ただ今回は2層基板のため、多層基板のAWの苦労には到底及ばない...)
全体の流れ
回路図作成・AW作成・基板製造を基板メーカーに依頼する。
基板到着後、部材を手配し手で実装。簡単なデザインを作成しMCUの動作を確認。
作るものとしてはTIのpiccoloの新しいMCUが気になっていたので、その評価ができればよいなという気持ちで作成。
Seeed Fusion で基板製造したわけ
安さと所要日数が短かったこと、日本語対応可であったため。
AW後にせっかくなので基板製造をしたくなったが、P版.comでは2万円を超える。
個人の勉強には多額であるため断念。
調べるとSeeedFusionが4.9ドルで基板製造してくれそうだ。しかし安くて不安...
送料込みで24.9ドル(送料20ドル)であったため、ダメージも少ないので依頼してみた。
(当時は合計15ドルで5枚製造と送料込みもあったようだ。)
各フェーズの概要
各作業工程の一覧と使用するツールはこんな感じです。
- 回路設計:TOOL:quadcept(←OrcadLiteデータコンバート)
- AW設計:TOOL:quadcept
- 基板製造:SeeedFusionにて依頼
- 部品手配:Mouserにて主要部品を手配
- 実装:手実装
- MCU開発環境:Code Composer Studio IDE(TI)
回路設計
MCUを中心とした回路図を作成。
OrcadPCBで作成し、quadceptにコンバート。
(OrcadツールではFusionSeeedでは具体的な提出ファイルがわからなかったため)
GPIOは基本的に外に出す。電源にはフィルタをかませる。
内蔵DCDCの機能が気になっているので、一応使えるように回路を引いてみた。
評価用のLEDを実装したいが、MCUの端子からドライブするのはしょっぱい。
シンクさせると電源パターンが引きにくくなるので結局ドライブとした。
最後の良心として実装部品にて5mA以下の電流に調整することにしよう。

PCB設計
- 表面
ほとんどの配線を表面に。自身のはんだスキル(下手)を考慮し、チップ品はすべて1608とした。

- 裏面
裏はGNDベタ(デジタル、アナログ)と電源パターン。
左下はアナログGNDでそれ以外はデジタルGNDとしている。
部品がちょっと乗っているのはDCDCの外付けインダクタの周り。

2層しかないのであまり気を使っても意味がないが、以下を意識...
- 裏面はできるだけGNDベタとなるように
- アナログGNDの分離(1点接続)
- デバイスの直下はGNDベタにし、シールド効果を期待
基板製造
注文後の処理。ただし2日後にドリルデータがないと言われたため、すぐに再提出。
- 2019-08-14 ご注文を承りました。
- 2019-08-14 お支払い情報は確認済み、すぐにご注文を処理いたします。
- 2019-08-14 ご注文は確認済み、生産プロセスに入りました。
←ドリルデータに関するメールのやり取りは中国の担当者と日本語で対応。怪しい部分もあるが、わかりやすい日本語で簡潔に書けば大丈夫だった。
ドリルデータ再提出後のプロセス
- 2019-08-16 ご注文を承りました。
- 2019-08-17 お支払い情報は確認済み、すぐにご注文を処理いたします。
- 2019-08-17 ご注文は確認済み、生産プロセスに入りました。
※16日(金)の夜に再提出。17日18日は土日のため、19日に製造スタート
- 2019-08-21 ご注文は梱包され、すぐに出荷されます。
- 2019-08-21 ご注文は出荷されました。すぐに配送状況を更新いたします。
- 2019-08-22 成田空港到着
- 2019-08-23 荷物到着
所要日数は10日間であった。但しデータに不足があったため、実際は8日間(土日含む)と思う。
さらにこれは土日もはさんでいるため、3営業日で発送→到着まで3日であれば6日間で受け取ることも可能と思われる。
到着基板
基板が10枚届いた。
QFP64pinのパッドの間にレジストが流れているのと流れていないのがあるように見えた。
0.5mmピッチ(PAd0.3mm間隔0.2mm以下)なのでかなり細かいと思う。
手実装で焦がすことを想定して黒いレジストにしたがそれが仇になったか...

実装と評価
手実装を実施。MCUを乗せるのが難しかった。
(1000円のMCUを1個破壊。フラックスの力を借りつつ何とか実装。)
JTAGでアクセスできることを確認し、LED点滅のテストデザインを作成した。(CCS:TI)
以下の写真ではD2,D3が交互に点滅する。

JTAGエミュレータにはTMS320-XDS100-V3(Olimex)を使用。(左側の赤い基板)
JTAG接続時は以下に注意
- VTRefに3.3Vを入力する。
- TDISをGNDに接続する。
TMS320F28004Xの必要なコード類はC2000WAREにあった。(ControlSuitは無し)
ControlSuit→C2000WARE
感想
500円で基板ができることは魅力的だと思った。また1週間程度で手元に届くのも早いと思う。
品質に多少疑問はあるが、趣味の範囲や実験の治具であれば十分だと感じた。今回は手実装がだるかった(&下手)ので、次は実装サービスを使ってみたい。
FF(フリップフロップ)の構成と仕組みを考える
はじめに
デジタル回路つくるとエッジでデータを保持するFFの恩恵はたくさん受ける。
ただ「FFって何だろう?」と思うことがある。
働き始めて数年、「FFってわかる?」みたいな質問を何回か受けたのだが、どんな回答を期待されてたのだろう。
本を読んでも何とかラッチを組み合わせるとDFFができると書いてあるがピンとこない。
説明はわかる(?)けど、本当に保持されるのとか頭が良くないから思ってしまう。
ある書物に46個のトランジスタの組み合わせでできると書いてあったので、わからないなりにつくってみることにした。
多分こんな道筋になると思う。

といってもICをはんだ付けしてオシロで見るのは大変だ。
回路シミュレータの「LTspice」を使うことにしよう。
PMOSとNMOS
最初にPMOSとNMOSのFETを復習する。

正確にはMOSFET(metal-oxide-semiconductor field-effect transistor)
金属-酸化物-半導体でMOSという。ポリシリコンは半金属だが、ゲートは歴史的に金属で作られてたらしいのでそう呼ぶらしい。
NOT
NOT回路はPMOSとNMOSを用いて以下のように作成する。
NMOSはGND側(PullDownの役目)に、PMOSは電源側(PullUpの役目)に配置する。
NMOSはゲートに正電圧を与える(-を誘起)ため、ゲートが正の時にGNDにPullDownする役目を担う。
PMOSはゲートに負電圧を与える(+を誘起)ため、ゲートが負の時にHighレベルにPullUpする役目を担う。
GateがHighの時にHighを出すような作り方はGate電圧がなくなるのでできない。NOTとして使いたくないならもう一度NOTを介して元に戻す。(バッファ)

| 入力 | 出力 |
|---|---|
| 0 | 1 |
| 1 | 0 |
NOR
NOR回路はPMOSとNMOSを用いて以下のように作成する。
NMOSを並列にして、NOR条件をつくる。そのためPMOSは直列となる。(端子が浮かないように...)

| 入力S00 | 入力S01 | 出力 |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 1 | 0 |
ORを作りたいときは出力にNOTを追加すればよい。素子数は4つ→6つと増える。
NAND
NAND回路はPMOSとNMOSを用いて以下のように作成する。
NOTを直列にして、NAND条件をつくる。そのためPMOSは並列となる。(端子が浮かないように...)

緑・・・入力S00 青・・・入力S01 赤・・・出力
| 入力S00 | 入力S01 | 出力 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 1 |
ANDを作りたいときは出力にNOTを追加すればよい。同様に素子数は4つ→6つと増える。
NORラッチ
NOTを使うと値が保持できます。ここにOR条件を加えると保持している値を0にしたり1にしたりできます。
これがNORラッチです。NANDでもできます。(ですが、NORのほうがわかりやすいです。)

NORラッチ回路はPMOSとNMOSを用いて以下のように作成する。

| リセットS00 | セットS01 | 出力Q |
|---|---|---|
| 0 | 0 | データ保持 |
| 1 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 1 | X(禁止) |
Resetで出力Qが0となり、setで出力Qが1となる。
リセット1、セット1は論理的な矛盾が起こるため、禁止入力である。実際素子がどのようなふるまいをしうる可能性があるのか?気になる...
Dラッチ
DラッチはNORラッチにCLKでゲートしたデータを入力している。セットはクロック&データ1、リセットはクロック&データ0となる。
クロックがHIGHの時にDataの0か1によりセット/リセットを操作している。
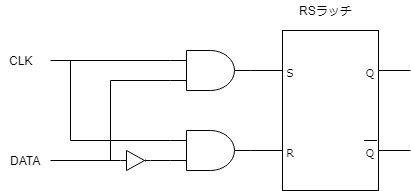
DラッチはPMOSとNMOSを用いて以下のように作成する。
素子数は22個になる。

| 入力CLK | 入力DATA | 出力 |
|---|---|---|
| 0 | 0 | データ保持 |
| 1 | 0 | 0 |
| 0 | 1 | データ保持 |
| 1 | 1 | 1 |
CLKが0の時はデータを保持する。ただし、クロック1の期間中にデータが変化すると出力もそのまま変化する。
パイプライン的に流し作業をするときに前の人の結果が早く来すぎてしまったり、作業中に論理が変わったりと不都合があるので、クロックの立ち上がりエッジだけでデータを更新したい。
それを実現するのはDFF(Delay-Flip-Plop)である。
DFF

1段目のDラッチはCLKのLOWで値を取り込む。2段目のDラッチはCLKのHIGHで値を取り込む。
1段目のDラッチはCLKがHIGHではデータを保持する。
2段目のDラッチはCLKがHIGHの間は手前のDラッチの保持値で一定に保たれ、CLKがLOWでは2段目のDラッチが保持を行う。CLKを反転させ、2段のDラッチを用いることで、CLKがLOWでは1段目が、CLKがHIGHでは2段目がデータを保持して1クロックのデータの保持を達成している。
そのため、1段目のDATAのCLK立ち上がり直前のデータが次の立ち上がりエッジまで保持される。
素子数は46個(D-latch*2+NOT)になる。
DFFはPMOSとNMOSを用いて以下のように作成する。


ピンク・・・CLK
緑・・・DATA
青・・・Dラッチ(1)中間出力
赤・・・出力
| 入力CLK | 入力DATA | 出力 |
|---|---|---|
| ↑以外 | 0 | データ保持 |
| ↑以外 | 1 | データ保持 |
| ↑ | 0 | 0 |
| ↑ | 1 | 1 |
これでDFFができた。
その他 論理
XOR
入力ABの反転を生成し、全パターン網羅。素子数12個。

NANDとNORで構成。素子数10個。
こちらの場合はクリティカルパスが12個使用した場合と同様の2段のため、素子数を減らしつつなおかつ速度を落とさない方法であると思われる。

最後に
DFFをFETを組み合わせて作ることができたが、これでもまだまだ不思議な気持ちが残る。結局、調べれば調べるほどわからないことが増えていく。
しかしながら思いつた先人もすごいなと思う。私が年をとってもFFは不思議だと言っていそう。(そのころはトランジスタベースが終わっていることを期待。)
この記事はまだまだ至らない部分が多々あるので、少しずつ更新していきたい。
参考資料
・デジタル回路設計とコンピュータアーキテクチャ
David Money Harris (著), Sarah L. Harris (著),
鈴木 貢 (翻訳), 天野 英晴 (翻訳), 中條 拓伯 (翻訳), 永松 礼夫 (翻訳)
FPGAのIODELAYの可変遅延を動作させてみる(Xilinx7シリーズ )
はじめに
ARTY評価ボード(Artix7)を用いてFPGAのIOに実装されている遅延タップを動かしてみる。

IDELAYシンボルを使用すると、80ps単位で遅延をさせられるらしい。(リファレンスクロック:200MHZ)
使い道はあったりなかったりだと思うが、とりあえず動かしてみよう。
接続図
IDELAYシンボルを以下のようにつないでみる。
各遅延シンボルは固定遅延(800psぐらい)+80ps×32tapの遅延をするようである。
4つのシンボルをつなぐと一番下のOUT4は 0ns-10ns の遅延可変ができそうだ。

FPGAデザイン
IO_DELAYのソースをVerilogで作成した。
これ以外のFPGAソースは※1にGithubのリンクを記載。
// io_delay_module.v // author:manaka // date:20/07/19 // Description:First // History // module io_delay_module ( input rst ,input clk ,input rst_reg ,output rdy ,input di_01 ,output do_01 ,input ldcnt_01 ,input [4:0] dicnt_01 ,output [4:0] docnt_01 ,input di_02 ,output do_02 ,input ldcnt_02 ,input [4:0] dicnt_02 ,output [4:0] docnt_02 ,input di_03 ,output do_03 ,input ldcnt_03 ,input [4:0] dicnt_03 ,output [4:0] docnt_03 ,input di_04 ,output do_04 ,input ldcnt_04 ,input [4:0] dicnt_04 ,output [4:0] docnt_04 ); // IDELAYCTRL: IDELAY/ODELAY Tap Delay Value Control 7 Series // Xilinx HDL Libraries Guide, version 13.1 (* IODELAY_GROUP = "test_io_delay" *) // Specifies group name for associated IODELAYs and IDELAYCTRL IDELAYCTRL IDELAYCTRL_inst ( .RDY (rdy ), // 1-bit Ready output .REFCLK (clk ), // 1-bit Reference clock input .RST (rst ) // 1-bit Reset input ); // End of IDELAYCTRL_inst instantiation // IDELAYE2: Input Fixed or Variable Delay Element // 7 Series // Xilinx HDL Libraries Guide, version 2012.2 // IDELAYE2 output1 (* IODELAY_GROUP = "test_io_delay" *) // Specifies group name for associated IDELAYs/ODELAYs and IDELAYCTRL IDELAYE2 #( .CINVCTRL_SEL ("FALSE" ), // Enable dynamic clock inversion (FALSE, TRUE) .DELAY_SRC ("DATAIN" ), // Delay input (IDATAIN, DATAIN) .HIGH_PERFORMANCE_MODE ("FALSE" ), // Reduced jitter ("TRUE"), Reduced power ("FALSE") .IDELAY_TYPE ("VAR_LOAD" ), // FIXED, VARIABLE, VAR_LOAD, VAR_LOAD_PIPE .IDELAY_VALUE (0 ), // Input delay tap setting (0-31) .PIPE_SEL ("FALSE" ), // Select pipelined mode, FALSE, TRUE .REFCLK_FREQUENCY (200.0 ), // IDELAYCTRL clock input frequency in MHz (190.0-210.0). .SIGNAL_PATTERN ("DATA" ) // DATA, CLOCK input signal ) IDELAYE2_i01 ( .CNTVALUEOUT (docnt_01 ), // 5-bit output: Counter value output .DATAOUT (do_01 ), // 1-bit output: Delayed data output .C (clk ), // 1-bit input: Clock input .CE (1'b0 ), // 1-bit input: Active high enable increment/decrement input .CINVCTRL (1'b0 ), // 1-bit input: Dynamic clock inversion input .CNTVALUEIN (dicnt_01 ), // 5-bit input: Counter value input .DATAIN (di_01 ), // 1-bit input: Internal delay data input .IDATAIN (1'b0 ), // 1-bit input: Data input from the I/O .INC (1'b0 ), // 1-bit input: Increment / Decrement tap delay input .LD (ldcnt_01 ), // 1-bit input: Load IDELAY_VALUE input .LDPIPEEN (1'b0 ), // 1-bit input: Enable PIPELINE register to load data input .REGRST (rst_reg ) // 1-bit input: Active-high reset tap-delay input ); // IDELAYE2 output2 (* IODELAY_GROUP = "test_io_delay" *) // Specifies group name for associated IDELAYs/ODELAYs and IDELAYCTRL IDELAYE2 #( .CINVCTRL_SEL ("FALSE" ), // Enable dynamic clock inversion (FALSE, TRUE) .DELAY_SRC ("DATAIN" ), // Delay input (IDATAIN, DATAIN) .HIGH_PERFORMANCE_MODE ("FALSE" ), // Reduced jitter ("TRUE"), Reduced power ("FALSE") .IDELAY_TYPE ("VAR_LOAD" ), // FIXED, VARIABLE, VAR_LOAD, VAR_LOAD_PIPE .IDELAY_VALUE (0 ), // Input delay tap setting (0-31) .PIPE_SEL ("FALSE" ), // Select pipelined mode, FALSE, TRUE .REFCLK_FREQUENCY (200.0 ), // IDELAYCTRL clock input frequency in MHz (190.0-210.0). .SIGNAL_PATTERN ("DATA" ) // DATA, CLOCK input signal ) IDELAYE2_i02 ( .CNTVALUEOUT (docnt_02 ), // 5-bit output: Counter value output .DATAOUT (do_02 ), // 1-bit output: Delayed data output .C (clk ), // 1-bit input: Clock input .CE (1'b0 ), // 1-bit input: Active high enable increment/decrement input .CINVCTRL (1'b0 ), // 1-bit input: Dynamic clock inversion input .CNTVALUEIN (dicnt_02 ), // 5-bit input: Counter value input .DATAIN (di_02 ), // 1-bit input: Internal delay data input .IDATAIN (1'b0 ), // 1-bit input: Data input from the I/O .INC (1'b0 ), // 1-bit input: Increment / Decrement tap delay input .LD (ldcnt_02 ), // 1-bit input: Load IDELAY_VALUE input .LDPIPEEN (1'b0 ), // 1-bit input: Enable PIPELINE register to load data input .REGRST (rst_reg ) // 1-bit input: Active-high reset tap-delay input ); // IDELAYE2 output3 (* IODELAY_GROUP = "test_io_delay" *) // Specifies group name for associated IDELAYs/ODELAYs and IDELAYCTRL IDELAYE2 #( .CINVCTRL_SEL ("FALSE" ), // Enable dynamic clock inversion (FALSE, TRUE) .DELAY_SRC ("DATAIN" ), // Delay input (IDATAIN, DATAIN) .HIGH_PERFORMANCE_MODE ("FALSE" ), // Reduced jitter ("TRUE"), Reduced power ("FALSE") .IDELAY_TYPE ("VAR_LOAD" ), // FIXED, VARIABLE, VAR_LOAD, VAR_LOAD_PIPE .IDELAY_VALUE (0 ), // Input delay tap setting (0-31) .PIPE_SEL ("FALSE" ), // Select pipelined mode, FALSE, TRUE .REFCLK_FREQUENCY (200.0 ), // IDELAYCTRL clock input frequency in MHz (190.0-210.0). .SIGNAL_PATTERN ("DATA" ) // DATA, CLOCK input signal ) IDELAYE2_i03 ( .CNTVALUEOUT (docnt_03 ), // 5-bit output: Counter value output .DATAOUT (do_03 ), // 1-bit output: Delayed data output .C (clk ), // 1-bit input: Clock input .CE (1'b0 ), // 1-bit input: Active high enable increment/decrement input .CINVCTRL (1'b0 ), // 1-bit input: Dynamic clock inversion input .CNTVALUEIN (dicnt_03 ), // 5-bit input: Counter value input .DATAIN (di_03 ), // 1-bit input: Internal delay data input .IDATAIN (1'b0 ), // 1-bit input: Data input from the I/O .INC (1'b0 ), // 1-bit input: Increment / Decrement tap delay input .LD (ldcnt_03 ), // 1-bit input: Load IDELAY_VALUE input .LDPIPEEN (1'b0 ), // 1-bit input: Enable PIPELINE register to load data input .REGRST (rst_reg ) // 1-bit input: Active-high reset tap-delay input ); // IDELAYE2 output4 (* IODELAY_GROUP = "test_io_delay" *) // Specifies group name for associated IDELAYs/ODELAYs and IDELAYCTRL IDELAYE2 #( .CINVCTRL_SEL ("FALSE" ), // Enable dynamic clock inversion (FALSE, TRUE) .DELAY_SRC ("DATAIN" ), // Delay input (IDATAIN, DATAIN) .HIGH_PERFORMANCE_MODE ("FALSE" ), // Reduced jitter ("TRUE"), Reduced power ("FALSE") .IDELAY_TYPE ("VAR_LOAD" ), // FIXED, VARIABLE, VAR_LOAD, VAR_LOAD_PIPE .IDELAY_VALUE (0 ), // Input delay tap setting (0-31) .PIPE_SEL ("FALSE" ), // Select pipelined mode, FALSE, TRUE .REFCLK_FREQUENCY (200.0 ), // IDELAYCTRL clock input frequency in MHz (190.0-210.0). .SIGNAL_PATTERN ("DATA" ) // DATA, CLOCK input signal ) IDELAYE2_i04 ( .CNTVALUEOUT (docnt_04 ), // 5-bit output: Counter value output .DATAOUT (do_04 ), // 1-bit output: Delayed data output .C (clk ), // 1-bit input: Clock input .CE (1'b0 ), // 1-bit input: Active high enable increment/decrement input .CINVCTRL (1'b0 ), // 1-bit input: Dynamic clock inversion input .CNTVALUEIN (dicnt_04 ), // 5-bit input: Counter value input .DATAIN (di_04 ), // 1-bit input: Internal delay data input .IDATAIN (1'b0 ), // 1-bit input: Data input from the I/O .INC (1'b0 ), // 1-bit input: Increment / Decrement tap delay input .LD (ldcnt_04 ), // 1-bit input: Load IDELAY_VALUE input .LDPIPEEN (1'b0 ), // 1-bit input: Enable PIPELINE register to load data input .REGRST (rst_reg ) // 1-bit input: Active-high reset tap-delay input ); endmodule
CPUの制御
100msごとに1TAPずつ増やしていく処理を作成した。
/* * test application * ------------------------------------------------ * | UART TYPE BAUD RATE | * ------------------------------------------------ * uartns550 9600 * uartlite Configurable only in HW design * ps7_uart 115200 (configured by bootrom/bsp) */ #include <stdlib.h> #include <stdio.h> #include "xil_printf.h" #include "xparameters.h" #include "xil_cache.h" #include "xintc.h" #include "xgpio.h" #include "xiic.h" XGpio Gpio; /* The Instance of the GPIO Driver */ // include lib src #include "sleep.h" #include "platform.h" #define GPIOPS_BASE (0x40000000) #define LED_ADDR (0x40010000) #define IO_DELAY_01 (0x40020000) int main() { // variable u32 reg_u32_buf; // main process init_platform(); print("IO Delay Test Start\n\r"); while (1) { // init delay value XGpio_WriteReg(0x40020000, 0x00, 0x00000000);// initialize delay count XGpio_WriteReg(0x40020000, 0x00, 0x20202020);// load enable XGpio_WriteReg(0x40020000, 0x00, 0xDFDFDFDF);// load disable // loop delay 1 for (u8 i = 0; i <= 31; i++){ reg_u32_buf = 0x000000FF & i ; XGpio_WriteReg(0x40020000, 0x00, reg_u32_buf); // Set 1b at bit5 reg_u32_buf |= 0x00000020 ; XGpio_WriteReg(0x40020000, 0x00, reg_u32_buf); // Set 0b at bit5 reg_u32_buf &= 0xFFFFFFDF ; XGpio_WriteReg(0x40020000, 0x00, reg_u32_buf); usleep_MB(100000);//100ms }; // loop delay 2 for (u8 i = 0; i <= 31; i++){ reg_u32_buf = 0x0000FF00 & (i << 8) ; XGpio_WriteReg(0x40020000, 0x00, reg_u32_buf); // Set 1b at bit13 reg_u32_buf |= 0x00002000 ; XGpio_WriteReg(0x40020000, 0x00, reg_u32_buf); // Set 0b at bit13 reg_u32_buf &= 0xFFFFDFFF ; XGpio_WriteReg(0x40020000, 0x00, reg_u32_buf); usleep_MB(100000);//100ms }; // loop delay 3 for (u8 i = 0; i <= 31; i++){ reg_u32_buf = 0x00FF0000 & (i << 16) ; XGpio_WriteReg(0x40020000, 0x00, reg_u32_buf); // Set 1b at bit21 reg_u32_buf |= 0x00200000 ; XGpio_WriteReg(0x40020000, 0x00, reg_u32_buf); // Set 0b at bit21 reg_u32_buf &= 0xFFDFFFFF ; XGpio_WriteReg(0x40020000, 0x00, reg_u32_buf); usleep_MB(100000);//100ms }; // loop delay 4 for (u8 i = 0; i <= 31; i++){ reg_u32_buf = 0xFF000000 & (i << 24) ; XGpio_WriteReg(0x40020000, 0x00, reg_u32_buf); // Set 1b at bit29 reg_u32_buf |= 0x20000000 ; XGpio_WriteReg(0x40020000, 0x00, reg_u32_buf); // Set 0b at bit29 reg_u32_buf &= 0xDFFFFFFF ; XGpio_WriteReg(0x40020000, 0x00, reg_u32_buf); usleep_MB(100000);//100ms }; } }
チップスコープ評価
さすがに自宅にGサンプルができるオシロスコープはないので、チップスコープで見てみる。
可変遅延0の時。
OUT1,3はトリガと同じクロックでサンプルされている。OUT4は固定遅延分があり、次のクロックでサンプルされている。
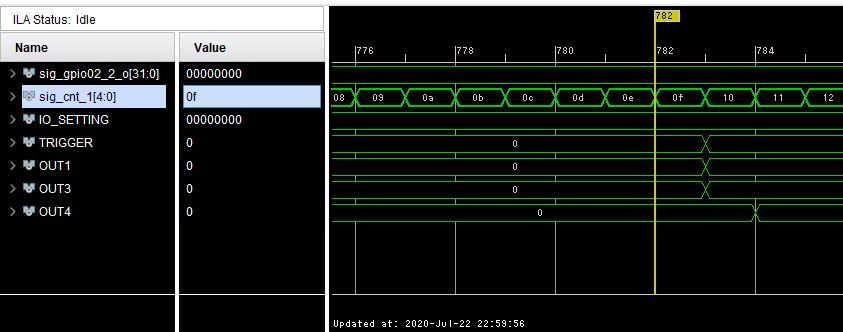
可変遅延最大の時。(+128TAP 10ns遅延)
OUT4は3クロック後にサンプルされている。
10ns遅延していることの裏付けとなる。
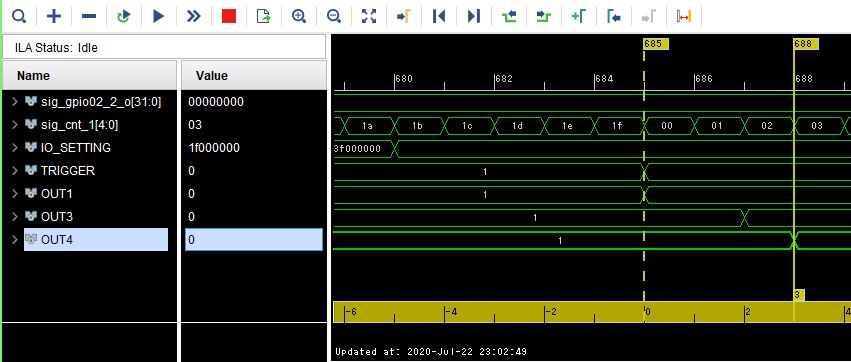
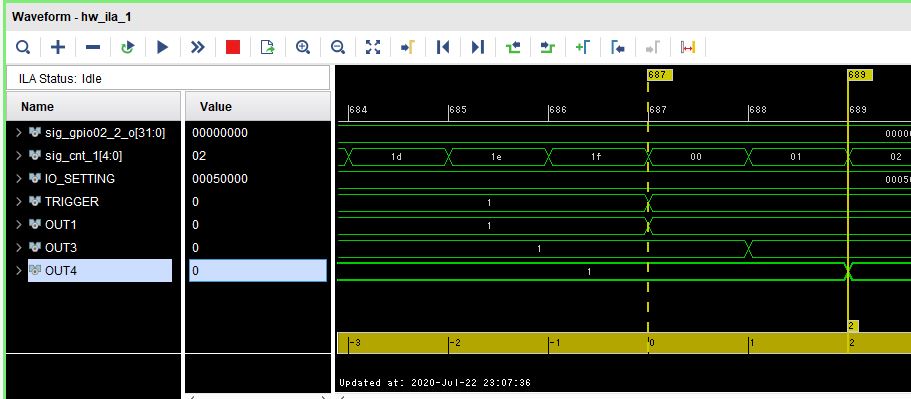
可変遅延最大の時。(+69TAP 5nsぐらい遅延)
トリガ+2CLKなので5nsは遅延ているようである。
オシロ評価
しかし実際は80psごとに波形がきれいにシフトしていくはずである。
高機能なオシロを拝借してみてみると、きれいに80psステップで遅延が増加していく波形が確認できた。
最後に
実際どんな時にこのシンボルを使うのだろうか?
高速なDDRのバスの微調整などだろうか?
気になる。
注釈
githubのソース準備中
可変アドレスデコーダ(Verilog)
概要
入力ビット数と出力ビット数が可変できるアドレスデコーダ。出力ビット数は2^入力ビット数とする。
アドレスデコーダを可変にする状況で使いまわせると思い作成。
テクノロジーマッピングで意図したLUTの個数になっているかみてみた。(Cyclone3デバイス 4入力-LUTを条件として確認)

ソースコード
decode_var.v
// decode_var.v // author:manaka // date:19/01/04 // Description:First // History // v0.1 create new // module decode_var #( parameter DATA_BITS = 4 // decoder inout bits ,parameter DCD_BITS = 16 // decoder output bits(2^DATA_BITS) ) ( input [DATA_BITS-1:0] data_in // decode_input ,output[DCD_BITS-1:0] decode_out // decode_output ); genvar dcd_lp ; // decode loop variable /* decoder */ generate for( dcd_lp = 0; dcd_lp < DCD_BITS; dcd_lp = dcd_lp + 1) begin : gen_dcd_lp assign decode_out[dcd_lp] = (data_in == dcd_lp )? 1'b1: 1'b0; end endgenerate endmodule
検証環境
- decode_var_tb.v
- decode_var_top.v TOPから入力データ幅と出力データ幅を定義
- D1.decode_var.v width:12 cycle数: 5
- D2.decode_var.v width:32 cycle数:11
- decode_var_top.v TOPから入力データ幅と出力データ幅を定義
decode_var_top.v
// decode_var_top.v // author:manaka // date:19/01/05 // Description:First // History // v0.1 create new // module decode_var_top( input [3:0] DATA_1_IN ,output [15:0] DECODE_1_OUT ,input [4:0] DATA_2_IN ,output [31:0] DECODE_2_OUT ); //------------------------------------ // decoder_var module //------------------------------------ defparam D1.DATA_BITS = 4 ; defparam D1.DCD_BITS = 16 ; decode_var D1( .data_in (DATA_1_IN) ,.decode_out (DECODE_1_OUT) ); defparam D2.DATA_BITS = 5 ; defparam D2.DCD_BITS = 32 ; decode_var D2( .data_in (DATA_2_IN) ,.decode_out (DECODE_2_OUT) ); endmodule
shift_reg_tb.v
// decode_var_tb.v // author:manaka // date:19/01/04 // Description:First // History // v0.1 create new // `timescale 1ps/1ps module decode_var_tb(); reg CLK ; reg RST ; reg [3:0] DATA_1_IN ; wire [15:0] DECODE_1_OUT ; reg [4:0] DATA_2_IN ; wire [31:0] DECODE_2_OUT ; integer i ; //------------------------------------ // decoder_var module //------------------------------------ decode_var_top top_inst( .DATA_1_IN ( DATA_1_IN ) ,.DECODE_1_OUT ( DECODE_1_OUT ) ,.DATA_2_IN ( DATA_2_IN ) ,.DECODE_2_OUT ( DECODE_2_OUT ) ); //------------------------------------ // Clock generator //------------------------------------ parameter CLK_PERIOD = 20000; // ps 20ns initial begin CLK = 1'b0; end always #(CLK_PERIOD/2) begin CLK <= ~CLK; end //------------------------------------ // Reset generator //------------------------------------ initial begin RST = 1 ; repeat(20) @(negedge CLK); RST = 0 ; end //------------------------------------ // Test //------------------------------------ initial begin DATA_1_IN= {4{1'b0}}; DATA_2_IN= {5{1'b0}}; @(negedge CLK); while(RST==0) @(negedge CLK); repeat(50) @(negedge CLK); // count up decoder // count up decoder for( i = 0; i < 16; i = i + 1) begin DATA_1_IN= DATA_1_IN + 1 ; repeat(10) @(negedge CLK); end for( i = 0; i < 32; i = i + 1) begin DATA_2_IN= DATA_2_IN + 1 ; repeat(10) @(negedge CLK); end $stop; end endmodule
検証結果
シミュレーション検証
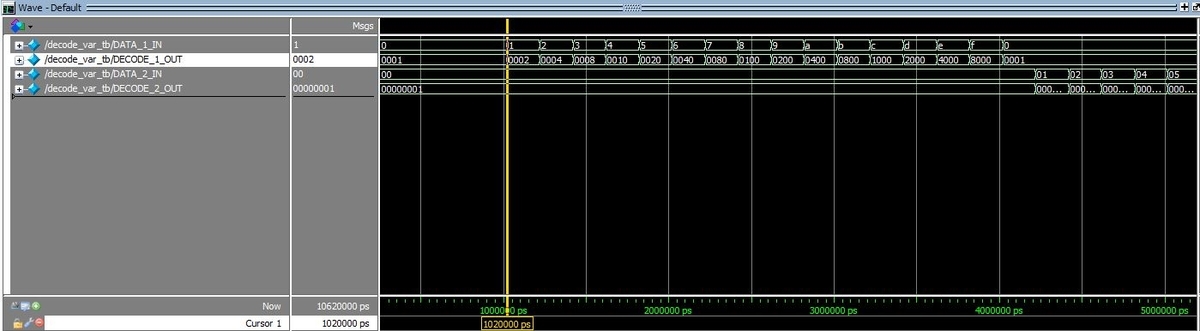
TOPで宣言したモジュールがパラメーターにより各bit幅でデコードされることを確認。
- 4bit 24=16bit幅でデコード
- 5bit 25=32bit幅でデコード

ツール合成(Quartus13.1)
RTL viewer
Quartusで合成し、RTLViewerを確認。比較器で表現されている。

テクノロジーマップ viewer
全体図

4bit→16bitのデコーダー
4bit→16bitのデコーダーは4入力LUT1段で済んでいる。
合成プロジェクトはCycloneIIIのため、4入力LUT。

5bit→32bitのデコーダー
5bit→32bitのデコーダーは4入力LUT1段では足りず、2段構成となる。
合成プロジェクトはCycloneIIIのため4入力LUTであるが、上位デバイスで6入力や8入力LUTであれば1段で済むと思われる。

RTLViewerは比較器で表現されてしまっているが、テクノロジーマップでのLUT段数は入力数に依存することは期待通りだった。
LUTの入力数を考えながらデコーダーを設計するとリソースを無駄にしなくて済みそうだ。(4入力LUT,6入力LUT,8入力LUTに合わせて設計するとか)
ただツールは頭がいいので、そんなこと意識しなくても最適化してくれるのかな。
遅延可変シフトレジスタ(VHDL)
概要
遅延サイクルと幅を設定可能なシフトレジスタのVHDL版です。
FF生成は本モジュールをパラメーターを変えて使いまわすと楽そう。
ModelSimで動作確認、Vivado2018.1にて実装確認をしました。

ソースコード
shift_reg.vhd
-- shift_reg.vhd -- author:manaka -- date:19/09/07 -- Description:First -- History -- v0.1 first -- Library library IEEE; use IEEE.std_logic_1164.all; -- entity entity SHIFT_REG is generic ( SHIFT_CYCLE : integer := 5 ; SHIFT_WIDTH : integer := 12 ); port ( RST : in std_logic; CLK : in std_logic; DATA_IN : in std_logic_vector( SHIFT_WIDTH - 1 downto 0); DATA_OUT : out std_logic_vector( SHIFT_WIDTH - 1 downto 0) ); end SHIFT_REG; -- architecture architecture RTL of SHIFT_REG is subtype DATA_WIDTH is std_logic_vector( SHIFT_WIDTH-1 downto 0 ); type DFF_ARRAY_WIRE is array ( SHIFT_CYCLE downto 0 ) of DATA_WIDTH; type DFF_ARRAY_REG is array ( SHIFT_CYCLE downto 1 ) of DATA_WIDTH; signal data_ff : DFF_ARRAY_WIRE; signal data_ff_r : DFF_ARRAY_REG; begin GEN_SHIFT: for reg_lp in 0 to SHIFT_CYCLE-1 generate process(RST,CLK) begin if(RST = '1')then data_ff_r(reg_lp+1) <= (others => '0'); elsif(CLK'event and CLK = '1')then data_ff_r(reg_lp+1) <= data_ff(reg_lp); end if; end process; end generate GEN_SHIFT; GEN_WIRE: for wire_lp in 1 to SHIFT_CYCLE generate data_ff(wire_lp) <= data_ff_r(wire_lp); end generate GEN_WIRE; -- external port -- data_ff(0) <= data_in ; data_out <= data_ff(SHIFT_CYCLE) ; end RTL;
検証環境
- shift_reg_tb.vhd
shift_reg_top.vhd
-- shift_reg_top.vhd -- author:manaka -- date:19/09/07 -- Description:First -- History -- v0.1 first -- Library library IEEE; use IEEE.std_logic_1164.all; -- entity entity SHIFT_REG_TOP is port ( RST : in std_logic; CLK : in std_logic; DATA_IN_01 : in std_logic_vector(11 downto 0); DATA_OUT_01 : out std_logic_vector(11 downto 0); DATA_IN_02 : in std_logic_vector(31 downto 0); DATA_OUT_02 : out std_logic_vector(31 downto 0); DATA_IN_03 : in std_logic_vector( 0 downto 0); DATA_OUT_03 : out std_logic_vector( 0 downto 0) ); end SHIFT_REG_TOP; -- architecture architecture RTL of SHIFT_REG_TOP is component SHIFT_REG is generic ( SHIFT_CYCLE : integer := 5 ; SHIFT_WIDTH : integer := 12 ); port ( RST : in std_logic; CLK : in std_logic; DATA_IN : in std_logic_vector( SHIFT_WIDTH - 1 downto 0); DATA_OUT : out std_logic_vector( SHIFT_WIDTH - 1 downto 0) ); end component; begin ------------------------ -- shift_reg module ------------------------ shift_reg_i1: SHIFT_REG generic map( SHIFT_CYCLE => 5, SHIFT_WIDTH => 12 ) port map( RST => RST, CLK => CLK, DATA_IN => DATA_IN_01, DATA_OUT => DATA_OUT_01 ); shift_reg_i2: SHIFT_REG generic map( SHIFT_CYCLE => 11, SHIFT_WIDTH => 32 ) port map( RST => RST, CLK => CLK, DATA_IN => DATA_IN_02, DATA_OUT => DATA_OUT_02 ); -- shorten Description shift_reg_i3: SHIFT_REG generic map(22,1)port map(RST,CLK,DATA_IN_03,DATA_OUT_03); -- shift_reg_i3: SHIFT_REG -- generic map( -- SHIFT_CYCLE => 22, -- SHIFT_WIDTH => 1 -- ) -- port map( -- RST => RST, -- CLK => CLK, -- DATA_IN => DATA_IN_03, -- DATA_OUT => DATA_OUT_03 -- ); end RTL;
shift_reg_tb.vhd
-- shift_reg.vhd -- author:manaka -- date:19/09/07 -- Description:First -- History -- v0.1 first -- Library library IEEE; use IEEE.std_logic_1164.all; use IEEE.std_logic_arith.all; -- entity entity SHIFT_REG_TB is end SHIFT_REG_TB; architecture SIM of SHIFT_REG_TB is signal CLK : std_logic; constant clk_period : time := 100 ns; signal RST : std_logic; signal DATA_IN_01 : std_logic_vector(11 downto 0); signal DATA_OUT_01 : std_logic_vector(11 downto 0); signal DATA_IN_02 : std_logic_vector(31 downto 0); signal DATA_OUT_02 : std_logic_vector(31 downto 0); signal DATA_IN_03 : std_logic_vector( 0 downto 0); signal DATA_OUT_03 : std_logic_vector( 0 downto 0); -- Test Module component SHIFT_REG_TOP is port ( RST : in std_logic; CLK : in std_logic; DATA_IN_01 : in std_logic_vector(11 downto 0); DATA_OUT_01 : out std_logic_vector(11 downto 0); DATA_IN_02 : in std_logic_vector(31 downto 0); DATA_OUT_02 : out std_logic_vector(31 downto 0); DATA_IN_03 : in std_logic_vector( 0 downto 0); DATA_OUT_03 : out std_logic_vector( 0 downto 0) ); end component; begin -- generate clk process begin CLK <= '1'; wait for clk_period/2; CLK <= '0'; wait for clk_period/2; end process; -- Instance0 shift_reg_top_i0: SHIFT_REG_TOP port map( RST => RST , CLK => CLK , DATA_IN_01 => DATA_IN_01 ,--: in std_logic_vector(11 downto 0); DATA_OUT_01 => DATA_OUT_01 ,--: out std_logic_vector(11 downto 0); DATA_IN_02 => DATA_IN_02 ,--: in std_logic_vector(31 downto 0); DATA_OUT_02 => DATA_OUT_02 ,--: out std_logic_vector(31 downto 0); DATA_IN_03 => DATA_IN_03 ,--: in std_logic_vector( 0 downto 0); DATA_OUT_03 => DATA_OUT_03 --: out std_logic_vector( 0 downto 0) ); -- INITIALIZE process begin RST <= '1'; DATA_IN_01 <= (others => '0'); DATA_IN_02 <= (others => '0'); DATA_IN_03 <= (others => '0'); wait for clk_period*10; RST <= '0'; wait for clk_period*10; DATA_IN_01 <= X"AAA"; DATA_IN_02 <= X"55555555"; DATA_IN_03 <= "1"; wait for clk_period*50; DATA_IN_01 <= (others => '0'); DATA_IN_02 <= (others => '0'); DATA_IN_03 <= (others => '0'); wait for clk_period*50; std.env.finish; end process; end SIM; configuration BEHAVIOR OF SHIFT_REG_TB IS for SIM end for; end BEHAVIOR;
検証結果
シミュレーション検証
TOPで宣言したモジュールがパラメーターにより遅延されることを確認。
- 12bit 5サイクル
- 32bit 11サイクル
- 1bit 22サイクル

ツール合成(Vivado2018.1)
verilogはintelのQuartus13.1で生成回路を確認したため、VHDL版はXilinxのVivado2018.1を用いて検証してみる。
Elaborated Design
Vivado2018.1にてElaborated Designを確認。FFが125サイクルと3211サイクルと1*22サイクル生成されている。



Synthesized Design
テクノロジーマッピングはDFFが並ぶわけでなくQuartusの時の経験上なにか工夫があると踏んでいたが、やはりありそうだ。
ただパッと見たところ何が起こっているかわからない。
i1-i3ができている。中を見てみると...

やはりFFの羅列ではなさそうだ。

i3(1bit32段シフト)を拡大してみる。

解析を行い以下の図に簡略化した。基本的にSRLC16Eまたは32Eが使用されている。これはLUTの分散メモリをFF的に使用できる仕組みのようである。
これだけでもFFの仕組みが完成しそうだが、遅延させた'1'信号とANDさせている。おそらく分散メモリの指定アドレスまでデータが詰まるまでに意図しない値が出ないようにするための処理と推測される。
ゲートのためのシフト信号を作るためにFDCE(プリミティブ:D Flip-Flop with Clock Enable and Asynchronous
Clear)を1番シフトが大きいシンボルで生成し、あとは必要段数を他のロジックに渡して使いまわしている。

Xilinxの7シリーズアーキテクチャはさすがと感じたが、QuartusはCyclone3で見ていたためIntel(Altera)も同様になにかしら進化していると考えられる。
遅延可変シフトレジスタ(Verilog)
概要
遅延サイクルと幅を設定可能なシフトレジスタです。
意外とネットに記述が見当たらないので作成しました。
FF生成は本モジュールをパラメーターを変えて使いまわすと楽そう。
ModelSimで動作確認し、Quartus13.1にて実装確認を行いました。
LUTでやることをRTLで記述しFFは必要なときに入れると、FPGA(LUT&FF)ライクなソースコードになるような気がします。(根拠あんまり無し)
ソースコード
shift_reg.v
// shift_reg.v // author:manaka // date:19/01/04 // Description:First // History // v0.1 create new // module shift_reg #( parameter SHIFT_CYCLE = 5 ,parameter SHIFT_WIDTH = 12 ) ( input rst // reset ,input clk // clock ,input [SHIFT_WIDTH-1:0] data_in // data_input ,output[SHIFT_WIDTH-1:0] data_out // data_output ); genvar reg_lp ; // reg loop variable genvar wire_lp ; // wire loop variable reg [SHIFT_WIDTH-1:0] data_ff_r[SHIFT_CYCLE:1] ; // shift_reg wire [SHIFT_WIDTH-1:0] data_ff [SHIFT_CYCLE:0] ; // shift_wire /* shift register */ generate for(reg_lp = 0; reg_lp < SHIFT_CYCLE; reg_lp = reg_lp + 1) begin : gen_reg_lp always @(posedge clk or posedge rst) begin if(rst)begin data_ff_r[reg_lp+1] <= {SHIFT_WIDTH{1'b0}}; end else begin data_ff_r[reg_lp+1] <= data_ff[reg_lp]; end end end endgenerate generate for( wire_lp = 0; wire_lp < SHIFT_CYCLE; wire_lp = wire_lp + 1) begin : gen_wire_lp assign data_ff[wire_lp+1] = data_ff_r[wire_lp+1]; end endgenerate /* external port */ assign data_ff[0] = data_in ; assign data_out = data_ff[SHIFT_CYCLE] ; endmodule
検証環境
- shift_reg_tb.v
- shift_reg_top.v TOPからパラメーターでデータ幅とサイクル数を定義
- S1.shift_reg.v width:12 cycle数: 5
- S2.shift_reg.v width:32 cycle数:11
- S3.shift_reg.v width: 1 cycle数:22
- shift_reg_top.v TOPからパラメーターでデータ幅とサイクル数を定義
shift_reg_top.v
// shift_reg_tb.v // author:manaka // date:19/01/04 // Description:First // History // v0.1 create new // module shift_reg_top ( input RST // reset ,input CLK // clock ,input [11:0] DATA_1_IN // data_input ,output[11:0] DATA_1_OUT // data_output ,input [31:0] DATA_2_IN // data_input ,output[31:0] DATA_2_OUT // data_output ,input [0:0] DATA_3_IN // data_input ,output [0:0] DATA_3_OUT // data_output ); //------------------------------------ // shift_reg module //------------------------------------ defparam S1.SHIFT_CYCLE = 5 ; defparam S1.SHIFT_WIDTH = 12 ; shift_reg S1( .rst (RST) ,.clk (CLK) ,.data_in (DATA_1_IN) ,.data_out (DATA_1_OUT) ); defparam S2.SHIFT_CYCLE = 11 ; defparam S2.SHIFT_WIDTH = 32 ; shift_reg S2( .rst (RST) ,.clk (CLK) ,.data_in (DATA_2_IN) ,.data_out (DATA_2_OUT) ); defparam S3.SHIFT_CYCLE = 22; defparam S3.SHIFT_WIDTH = 1; shift_reg S3( .rst (RST) ,.clk (CLK) ,.data_in (DATA_3_IN) ,.data_out (DATA_3_OUT) ); endmodule
shift_reg_tb.v
// shift_reg_tb.v // author:manaka // date:19/01/04 // Description:First // History // v0.1 create new // `timescale 1ps/1ps module shift_reg_tb(); reg CLK ; reg RST ; reg [11:0] DATA_1_IN ; wire [11:0] DATA_1_OUT ; reg [31:0] DATA_2_IN ; wire [31:0] DATA_2_OUT ; reg [0:0] DATA_3_IN ; wire [0:0] DATA_3_OUT ; //------------------------------------ // shift_reg module //------------------------------------ shift_reg_top top_inst( .RST (RST ) ,.CLK (CLK ) ,.DATA_1_IN (DATA_1_IN ) ,.DATA_1_OUT (DATA_1_OUT ) ,.DATA_2_IN (DATA_2_IN ) ,.DATA_2_OUT (DATA_2_OUT ) ,.DATA_3_IN (DATA_3_IN ) ,.DATA_3_OUT (DATA_3_OUT ) ); //------------------------------------ // Clock generator //------------------------------------ parameter CLK_PERIOD = 20000; // ps 20ns initial begin CLK = 1'b0; end always #(CLK_PERIOD/2) begin CLK <= ~CLK; end //------------------------------------ // Reset generator //------------------------------------ initial begin RST = 1 ; repeat(20) @(negedge CLK); RST = 0 ; end //------------------------------------ // Test //------------------------------------ initial begin DATA_1_IN= {12{1'b0}}; DATA_2_IN= {32{1'b0}}; DATA_3_IN= {1{1'b0}}; @(negedge CLK); while(RST==0) @(negedge CLK); repeat(50) @(negedge CLK); DATA_1_IN= {12{1'b1}}; DATA_2_IN= {32{1'b1}}; DATA_3_IN= {1{1'b1}}; repeat(100) @(negedge CLK); DATA_1_IN= {12{1'b0}}; DATA_2_IN= {32{1'b0}}; DATA_3_IN= {1{1'b0}}; repeat(100) @(negedge CLK); $stop; end endmodule
検証結果
シミュレーション検証
TOPで宣言したモジュールがパラメーターにより遅延されることを確認。
- 12bit 5サイクル
- 32bit 11サイクル
- 1bit 22サイクル

ツール合成(Quartus13.1)
RTL viewer
Quartusで合成し、RTLViewerを確認。FFが125サイクルと3211サイクルと1*22サイクル生成されている。

テクノロジーマップ viewer
ロジックのFFが使用されると思っていたが、テクノロジーマップではRAMが使われている。
たくさんのシフトレジスタに各CellのFFを使うとLUTや配線リソースを効率的に使いづらくなる。そのため、RAMを使うようにツール側でつくられている。
FPGAリソースを効率的に使うために、ツール側が対応しているようだ。
(※この辺の特許はXilinxがLUTメモリはFFに使う方法をおさえているため、もしかしてRAM方法がとられているのか?VHDL編参照。)


FPGAプロジェクト生成自動化とソースコード管理(Vivado編)
概要
Vivadoを用いたFPGAのコード管理に関して記載します。 ソースコード(HDL、IP、BlockDesign,制約)を並べてバッチファイル(Windows)で自動生成する仕組みについて紹介します。 管理するファイルがソース関連だけになり、ある程度大規模なFPGAにおいても多くても数MByteです。 GITと連携しソースコード管理と複数人でのFPGA開発を容易にします。
※ArtixのMicroBlazeDesignのデモ(vivado2018.1)を紹介します。 github.com
背景
Vivadoを用いてFPGAをつくるときプロジェクトベースで管理すると容量が大きいファイルがたくさんできる。
たぶんIPの生成データとか中間データとか配置配線データとか含んでいる。
色々な日時のデータ(大規模だと1個1GByte超える)を保管しているとすぐにPCがパンクして困ってしまう。
FPGAのプロジェクトごと管理するのでなく、ソースコードだけ管理する仕組みを作りたい。
この辺はベンダーもたしか推奨していた手法な気がする。(うろ覚えですみません)
FPGAの作成フロー(ざっくり)
FPGAのプロジェクトフローを何となく書きます。
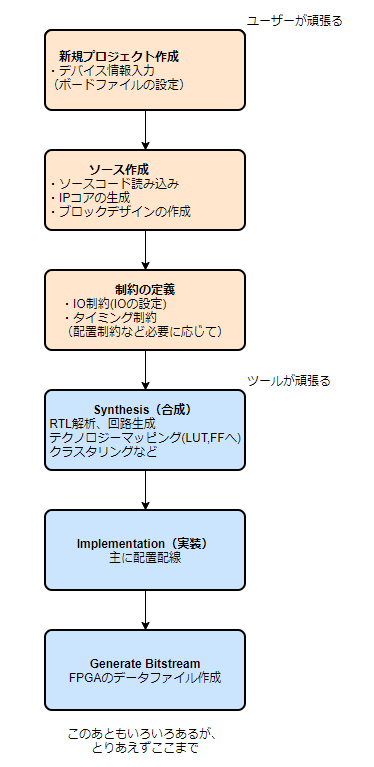
これを最初はGUIで作ると思います。(最初からコマンドモードで実施するすごい人もいるかもしれません。)
VivadoのGUIで作って、Bitstreamができて「おーよかったよかった」となるのですが、そのプロジェクトセット全体を今後も保管(管理?)し続けるのは大変です。
結局GUIをいじった挙句、必要になるのはおおよそ以下のファイルです。
・HDL(VHDL,Verilog)
・IPコアファイル (.xci)
・ブロックデザイン生成ファイル(.tcl)
・制約ファイル(.xdc)
このファイルだけを管理して、FPGA生成はバッチとTCLコマンドで自動化できるとプロジェクトファイルが軽くなります。
(もちろんリリースごとでは配置配線データを含むプロジェクトを残しておくと思います。)
デモのフォルダ構成
紹介するデモのフォルダ構成は大体こんな感じです。
・src ・・・HDL,Blockデザイン生成ファイル、IPファイル
・tcl ・・・制約ファイル
・xdc ・・・制約ファイル
・ReadMe.md
・build.bat
batを実行すると
・build フォルダが生成され
その下に日時フォルダ「 20200712-1253(西暦,月,日,-,時,分)」ができ、その下でツールが作業を始めます。
自動化の紹介
では一連の流れを自動化してみます。
Batファイルの起動からひとつひとつ記載いたします。(今回はWindowsですが、Linuxではシェルになると思います。)
(1)Vivado起動(非プロジェクトモード)
Build.batは以下の処理を行います。
(記事記載時点ではcompile.batとなってます。コンパイルとは意味が違うためBuild.batに修正予定。)
・Buildフォルダを作る。(Build日時と時間をファルダ名とする。)
2020年7月8日21時55分の場合は 20200708_2155というフォルダがbuildに生成される。
・Vivadoを非プロジェクトモードで起動
do_build.tclを与えて次にやることはこの中に入れております。
build.bat
@echo off set dt=%date% set tm=%time: =0% set FName=%dt:~-10,4%%dt:~-5,2%%dt:~-2,2%_%tm:~-11,2%%tm:~-8,2% mkdir build cd build mkdir %FName% cd %FName% xcopy ..\..\tcl tcl /D /S /R /Y /I /K C:\Xilinx\Vivado\2018.1\bin\vivado.bat -mode tcl -source tcl/do_build.tcl
(2)プロジェクト生成とソースインポート
do_build.tclの中は以下の通り。
build.bat
source tcl/import_project.tcl source tcl/run.tcl
import_project.tcl はだいたいフロー図のオレンジの部分です。 run.tcl はだいたいフロー図のブルーの部分です。
ではimport_projec.tclを見ていきます。
# Create project create_project arty_mb arty_mb -part xc7a35ticsg324-1L set_property board_part digilentinc.com:arty:part0:1.1 [current_project] # import source file source "../../src/mb/bd/arty_mb.tcl" add_files ../../src/mb/wrapper/arty_mb_wrapper.v add_files ../../src/top/arty_mb_top.v # import Ip core # import library # import constrs import_files -force #import_files -fileset constrs_1 -force -norecurse ../../xdc/system.xdc import_files -fileset constrs_1 -force -norecurse ../../xdc/arty_io.xdc import_files -fileset constrs_1 -force -norecurse ../../xdc/arty_timing.xdc
最初にデバイス名を指定してプロジェクトを作ります。
今回はArtyという評価ボード用プロジェクトのため、ボードのファイルを指定しています。
次にMicroBlazeとUARTコアを含んだブロックデザインを生成するtclを読み込みます。
これはGUIで作成した後、ExportBlockDesignで生成できます。本TCLを管理すればBlockデザインの差分を追えます。
(BlockDesignのレイアウトを管理することも可能ですが、今回は触れません。)
(3)合成と実装
次にrun.tclを見てみます。
SynthesisとImplementation,Bitstream生成とレポートの生成を行います。
# Mimic GUI behavior of automatically setting top and file compile order update_compile_order -fileset sources_1 update_compile_order -fileset sim_1 # Launch Synthesis launch_runs synth_1 wait_on_run synth_1 open_run synth_1 -name netlist_1 # Generate a timing and power reports and write to disk report_timing_summary -delay_type max -report_unconstrained -check_timing_verbose -max_paths 10 -input_pins -file ./syn_timing.rpt report_power -file ./syn_power.rpt # Launch Implementation launch_runs impl_1 -to_step write_bitstream wait_on_run impl_1 # Generate a timing and power reports and write to disk # comment out the open_run for batch mode open_run impl_1 report_timing_summary -delay_type min_max -report_unconstrained -check_timing_verbose -max_paths 10 -input_pins -file ./imp_timing.rpt report_power -file ./imp_power.rpt # comment out the for batch mode # start_gui # end exit
以上でFPGA生成の自動化ができました。
このソースコードと生成コマンド一式をGITで管理すればめでたくFPGAのコード管理ができるようになります。
本環境に関して
本環境はGitHubにあげております。
github.com
<環境>
・Vivado2018.1
・Vivadoが以下の場所にインストールされている。異なる場合はBatの該当部分を変えてください。
C:\Xilinx\Vivado\2018.1
・ArtyのBSPが入っていること。(※1に導入方法を記載。)
注釈
※1 Arty Board fileに関して
以下にArtyのBoardファイルがあります。
https://reference.digilentinc.com/reference/software/vivado/board-files?redirect=1
ダウンロードしてファイルを解凍します。
生成されたartyフォルダをVivadoインストールファルダのdata\boards\board_files に格納します。
最後に
ここまで読んでくださった方がおりましたらありがとうございます。
なかなかこの辺の手順に関しては情報があったりなかったりという気がします。
ISEツールでも同様の手順にてGITとの連携が可能ですが、環境構築していく上での情報がもっと少なく感じました...